About Logistic Regression
tags: #ML/supervised/classification/logit
What is the goal of binary classification?
The goal of binary classification is to define a decision boundary (hyperspace) in the D-dimensional feature space that can delineate the two classes:
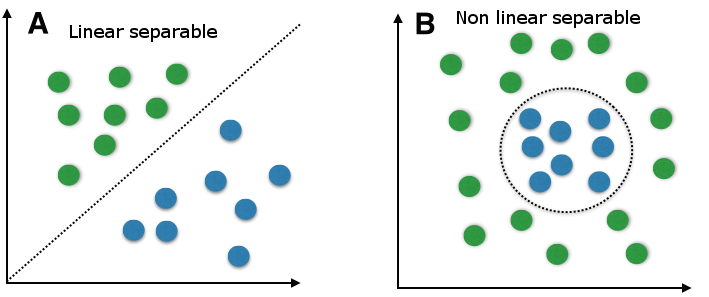
There are essentially two different methods for performing binary classification:
- #Binary Classification: Perceptron Learning Rule
- #Binary Classification: Logistic Regression using an activation function - why?
PLR does not work well with datasets that are not linearly separable; otherwise, it is a very effective algorithm on datasets that are LS.
Solutions: Use an activation function to convert the linear classifier into a probabilistic model.
The decision boundary in logistic regression is not a simple linear function like in the case of the perceptron algorithm. Instead, it is a non-linear function of the input features and weights, which allows for more flexibility in modeling complex relationships between the features and the classes by using an activation function (sigmoid) to model the probability of an instance belonging to the positive class.
This takes a linear combination of the input features and weights (z) and maps it to a value between 0 and 1, which represents the probability of the positive class.
Binary Classification: Perceptron Learning Rule
The Perceptron Learning Rule is a simple algorithm that seeks to find a linear decision boundary that can separate the two classes in the feature space.
How do we find the optimal decision boundary?
Binary classification works by computing a linear function and determining whether the output of the linear function, with respect to a given input vector, is greater than some threshold. We can mathematically define this boundary as
Therefore, the goal of logistic regression is to define a decision boundary parameterized by
How does the algorithm check for misclassification?
The algorithm checks for misclassification based on the following criterion:
If the criterion is NOT satisfied, an update is required.
Binary Classification: Logistic Regression
Logistic regression is also referred to as "logit".
Logit is also known as the log of odds.
How do we define a logistic regression model?
Logistic regression is used to predict the outcome of a dichotomous (binary) dependent variable with two categories; i.e., it is used to estimate the probability of a binary event occurring based on one or more independent variables by passing the output of the linear combination of the weights and its inputs + bias (
This restricts the predicted output into the required range of the target variable 0 and 1.
Why logistic regression vs PLR?
Logistic regression can handle both linearly and nonlinearly separable data, and can also handle cases where there are more than two classes. While Perceptron Learning Rule is often used for simple binary classification problems, it does not perform well for more complex datasets with nonlinear decision boundaries.
Interpreting the Logit
In logistic regression analysis, we do not model the probability of a binary event occurring directly, but we model the log odds of the event, also known as the logit function. The logit function is the natural logarithm of the odds ratio, which is the probability of the event divided by the probability of the complementary event:
Therefore, when interpreting the results of the estimated logistic regression parameters (coefficient,
Every 1 unit increase in X₁ is associated with b unit increase (or decrease) in the natural log of odds of event 1 occurring, while holding all other variables constant.
The odds ratio is:
This is quantified as how much more likely probability of the event is to occur relative to the probability of it not occurring.
Example:
If p of an event occurring is 0.8, then the odds of it occurring is:
Note that:
- Odds ratio approaches 1 is when the probability of success is equal to the probability of failure
Example: If the log odds value is 0, then what is the probability of success is?