About Decision Trees
tags: #ML/supervised/classification/trees
What are decision trees?
Decision tree is an unsupervised machine learning algorithm used for both classification and regression tasks.
How does it work?
It works by recursively splitting the dataset (repeatedly) into smaller binary nodes based on the feature of importance, which the algorithm determines based on the information gain contributed by the feature to the target variable.
How are predictions made?
Prediction is the made by transversing through the tree.
Example:
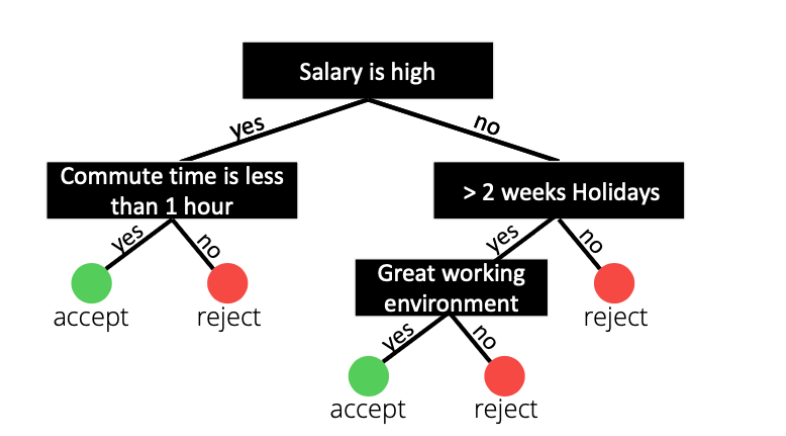
How does the algorithm select which features to split the data on?
The algorithm splits the data based on the information gain (IG) for each feature, which (recall) measures the reduction in entropy or how much the information the feature contributes to the increase in information about the target variable.
Importance of Hyper-parameters: Depth
The algorithm has an important hyperparameter when building a decision tree: Maximum depth.
- Refers to the maximum number of levels or nodes from the root of the tree to the leaf nodes.
The maximum depth of a decision tree has important implication on the:
- Complexity: Deeper trees can capture complex relationships and patterns in the data by splitting the data into more homogenous subsets, resulting in a more accurate representation of the underlying relationship in the data; however, this is often at the expense of lower generalizability.
- Interpretability: Shallow trees with limited depth are easier to interpret and understand.
- Generalizability: The deeper the tree, the less generalizable the algorithm is to previously unseen data, resulting in overfitting (which occurs when the model fails to capture the general pattern in the data and has instead memorize the training data, making it unable to generalize or adapt to unseen data).
- Efficiency: The deeper the tree, the more computationally intensive.
Overfitting is when a model fails to capture the general pattern in the data and has instead memorized the training data, and thus, is unable to adapt to unseen data.
Solution: Limit tree depth and rely on testing accuracy. Why?
- Models with larger tree depth are better able to capture the complexity of a data, but can lead to overfitting as it can fail to capture the general pattern.
- Limiting the depth of the tree can prevent overfitting by restricting the complexity of the tree and reducing the noisy patterns it can capture.
- Testing accuracy should not deviate too far from the training accuracy, which can otherwise be indicative of overfitting.
Address overfitting using k-fold CV
- Related: K-Fold Cross-Validation
K-fold cross-validation is an ideal approach in mitigating the overfitting of decision tree models by providing an unbiased measure of its generalizability on previously unseen data.