K-Fold Cross-Validation
tags: #python/data_science/model_selection
What is k-fold cross-validation?
In general, cross-validation is preferred when the data size is small or the modeling task is complex, while train/test/validation split is a good choice for larger datasets and simpler tasks.
Cross-validation is a technique used to evaluate machine learning models by splitting the data into multiple subsets or "folds".
How does this work?
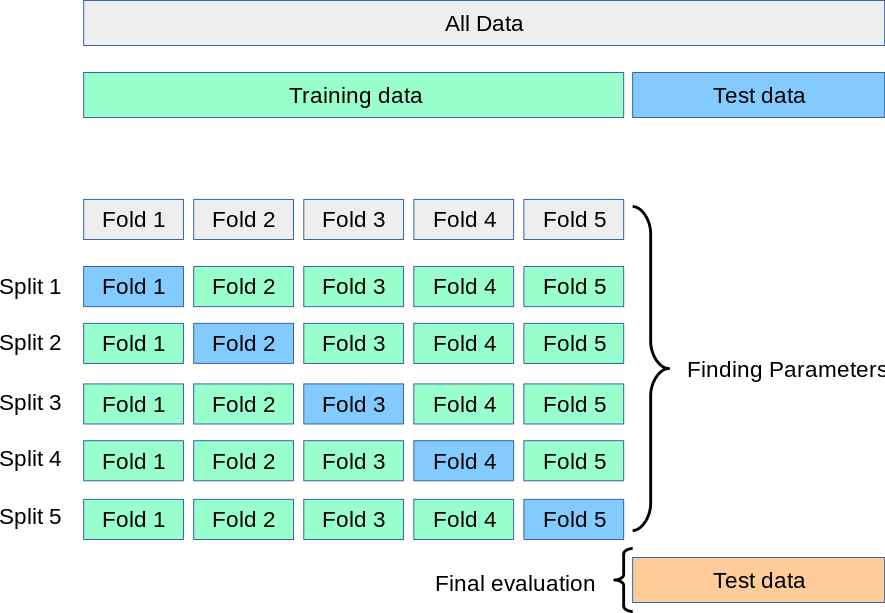
- K-fold Cross-Validation is when the dataset is split into a
K number of foldsand is used to evaluate the model's ability when given new data.
- i.e., K refers to the number of groups the data sample is split into.
- The algorithm repeatedly trains the model with
folds and tests the model with the remaining fold
How does this work in python?
We can implement k-fold cross validation using the KFold and cross_val_score function from the Scikit-Learn library’s model_selection module:
from sklearn.model_selection import KFold, cross_val_score
Python: kfold
The KFold method in scikit-learn allows you to specify/define split the data into k equal-sized folds to be used in cross-validation.
# define k-fold for cross-validation
kf = KFold(n_splits=5, random_state=0, shuffle=True)
Other variations of k-fold validation is with stratification (i.e., class proportions are preserved in each fold). Examples: RepeatedStratifiedKFold or StratifiedKFold.
- Generally ideal to use stratification when dealing with an imbalanced dataset.
- Stratification helps ensure that minority class(es) are not excluded from the training or testing set.
from sklearn.model_selection import RepeatedStratifiedKFold
# repeated
rskf = RepeatedStratifiedKFold(n_splits, n_repeats)
# single sampling
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
Both methods aim to address the issue of imbalanced datasets by ensuring the distribution of classes across all folds. The difference is that:
-
StratifiedkFoldperforms stratified sampling once to generate the k folds -
RepeatedStratifiedKfoldrepeats the process n number of times (can specify as a parameter). This produces n different sets of k folds, for more robust performance metric
Python: cross_val_score
To actually run the cross-validation, we use the cross_val_score function from scikit-learn. The split specified using the Kfold method is passed as an argument to the cv parameter:
from sklearn.model_selection import cross_val_score
# this returns an array of scores for the estimator for each k run of the validation
scores = cross_val_score(estimator = model, X, y, cv=kf)
# cv - is used to specify the cross-validation strategy -> using kfold
A performance score is generated for each
With each iteration, it trains the model on
This can be incorporated with training dataset as follows:
scores = cross_val_score(estimator = model, X_train, y_train, cv=kf)
Getting the accuracy
scores.mean()
We can specify the scoring method by specifying the score parameter:
scores = cross_val_score(estimator = model, X_train, y_train, cv=kf, score="accuracy")
If the score parameter is set to a string such as 'accuracy', then it will use the accuracy score to evaluate the model's performance. Other possible scoring methods include 'precision', 'recall', 'f1', 'roc_auc', and others, depending on the type of problem being addressed.